LangChain4j之快速入门
LangChain4j入门
简介
LangChain4j的目标,是简化将大语言模型(LLM - Large Language Model)集成到 Java 应用程序中的过程。
历史背景
2022年11月30日OpenAI发布了Chat GPT(GPT-3.5),而在同年10月,Harrison Chase 发布了基于Python的LangChain,随后同时包含了Python版和JavaScript(LangChain.js)版的LangChain 也发布了,直到2023年 11 月,Quarkus 发布了 LangChain4j 的0.1版本,2025年2月发布了1.0 - Beta1 版本,4月发布了1.0 - Beta4 版本,截止到10月18日,最新版本为1.7.1。
主要功能
(1)与大型语言模型和向量数据库的便捷交互。
通过统一的应用程序编程接口(API),可以轻松访问所有主要的商业和开源大型语言模型以及向量数据库,使你能够构建聊天机器人、智能助手等应用。
(2)专为Java打造。
借助SpringBoot集成,能够将大模型集成到java 应用程序中。大型语言模型与Java之间实现了双向集成,即你可以从Java中调用大型语言模型,同时也允许大型语言模型反过来调用你的Java代码。
(3)智能代理(Agent)、工具(Tools)、检索增强生成(RAG)。
应用示例
(1)你想要实现一个自定义的由人工智能驱动的聊天机器人,它可以访问你的数据,并按照你期望的方式运行:
- 客户支持聊天机器人,它可以礼貌地回答客户问题;
- 处理 / 更改 / 取消订单;
- 教育助手,它可以教授各种学科,解释不清楚的部分,评估用户的理解/知识水平。
(2)你想要处理大量的非结构化数据(文件、网页等),并从中提取结构化信息,如:
- 从客户评价和支持聊天记录中提取有效评价;
- 从竞争对手的网站上提取有趣的信息;
- 从求职者的简历中提取有效信息。
(3)你想要生成信息,如:
- 为你的每个客户量身定制的电子邮件;
- 为你的应用程序/网站生成内容,如博客文章或者故事、
(4)你想要转换信息,如:
- 总结;
- 校对和修改;
- 翻译。
创建SpringBoot项目
本项目基于JDK17、SpringBoot3.5、LangChain4j1.0.0-beta3搭建,这是主要版本说明。
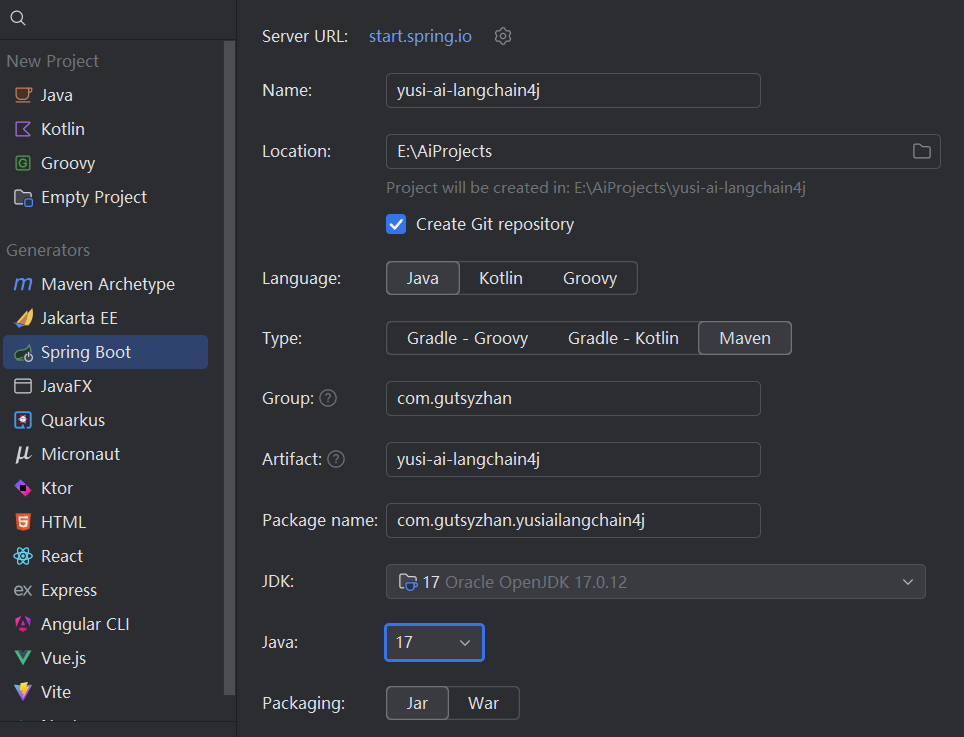
第一步,创建一个名为yusi-ai-langchain4j的项目:
第二步,在其pom文件的project节点中新增如下依赖:
1 | <properties> |
第三步,修改项目配置文件application.properties为如下所示:
1 | spring.application.name=yusi-ai-langchain4j |
第四步,启动项目,访问如下地址:
1 | http://localhost:8080/doc.html |
页面效果如下所示,则说明项目配置成功:
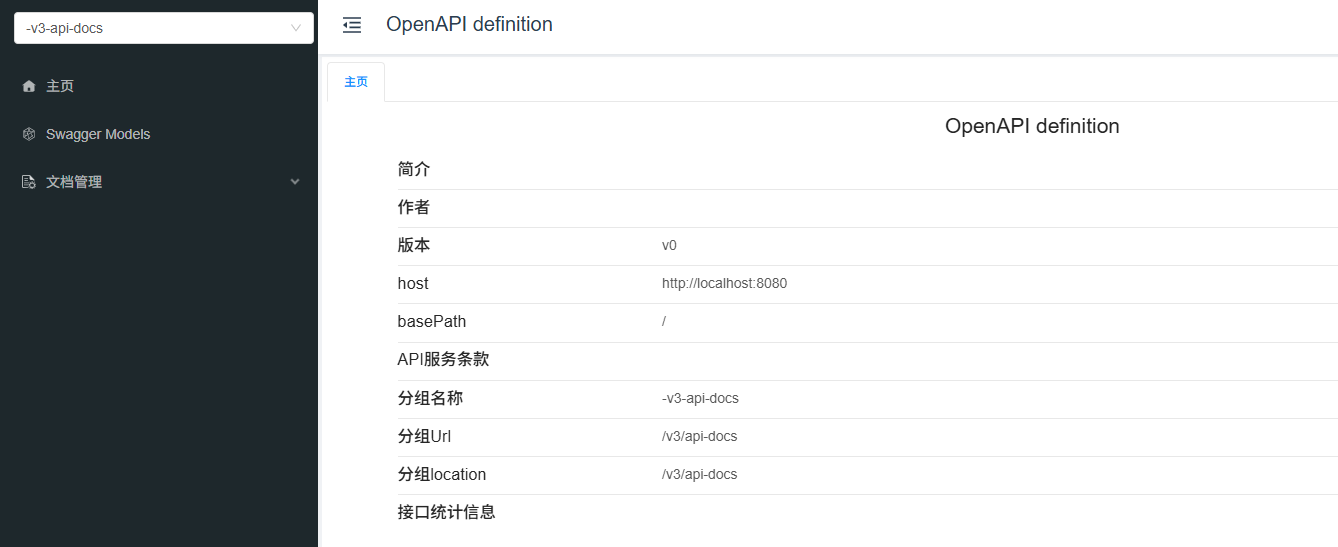
出现这个页面是因为我们使用了Knife4j ,它是一个 增强版的Swagger UI,用于在 Java 项目(尤其是 Spring Boot)中自动生成 接口文档。
开始使用
点击 这里 阅读对接文档,本部分内容就是对于该文档的学习和记录,注意这里先介绍的是与普通Maven项目的集成,后续会介绍与SpringBoot项目的集成。
LangChain4j的库结构
LangChain4j 具有模块化设计,包括三个模块,分别是langchain4j-core模块、主langchain4j模块以及集成模块:
(1)langchain4j-core模块:定义了核心抽象概念(如聊天语言模型和嵌入存储)及其 API;
(2)主langchain4j模块:包含很多工具,如文档加载器、聊天记忆实现,以及诸如人工智能服务等高层功能;
(3)大量的langchain4j-{集成}模块:每个模块都将各种大语言模型提供商和嵌入存储集成到LangChain4j中。开发者可以独立使用langchain4j-{集成}模块,如需更多功能,只需导入主langchain4j依赖项即可。
添加LangChain4j相关依赖
在项目的pom文件中新增如下依赖:
1 | <properties> |
创建测试用例
请注意,接入任何一个大模型都需要先去申请apiKey,如果你暂时没有密钥,也可以使用LangChain4j 提供的演示密钥,这个密钥是免费的,有使用配额限制,且仅限于gpt-4o-mini模型。
回到项目中,在其测试类的contextLoads方法中接入gpt-4o-mini模型进行测试:
1 | @SpringBootTest |
运行上述测试类,结果如下所示:
1 | 你好!我是一个人工智能助手,旨在回答问题和提供信息。有什么我可以帮助你的吗? |
上面我们使用的是LangChain4j提供的代理服务器,该代理服务器会将演示密钥替换成真实密钥,再将请求转发给OpenAI API,所以需要设置baseUrl,实际上如果你的apiKey为demo,则可省略baseUrl的配置:
1 | OpenAiChatModel model = OpenAiChatModel.builder() |
与SpringBoot整合
点击 这里 阅读相关文档,学习任何新技术,必须得阅读对应的文档,不然学的不够系统和全面。
替换依赖
将langchain4j-open-ai 替换成 langchain4j-open-ai-spring-boot-starter,更新依赖信息:
1 | <!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 --> |
配置模型参数
在项目的application.properties配置文件中,新增如下配置信息:
1 | #langchain4j测试模型 |
创建测试用例
在这种情况下,将自动创建一个实例OpenAiChatModel,开发者可以在需要的地方注入该实例,示例代码如下:
1 | @Autowired |
我们可以在测试类的contextChatModel方法中接入gpt-4o-mini模型进行测试:
1 | @SpringBootTest |
运行上述测试类,结果如下所示:
1 | 你好!我是一个人工智能助手,旨在回答你的问题和提供帮助。你有什么需要了解的呢? |
大模型评测基准
SuperCLUE 是由国内 CLUE 学术社区于 2023 年 5 月推出的中文通用大模型综合性评测基准:
(1)评测目的。全面评估中文大模型在语义理解、逻辑推理、代码生成等 10 项基础能力,以及涵盖数学、物理、社科等 50 多学科的专业能力,旨在回答在通用大模型发展背景下,中文大模型的效果情况,包括不同任务效果、与国际代表性模型的差距、与人类的效果对比等问题。
(2)特色优势。针对中文特性任务,如成语、诗歌、字形等设立专项评测,使评测更符合中文语言特点。通过 3700 多道客观题和匿名对战机制,动态追踪国内外主流模型,如 GPT-4、文心一言、通义千问等的表现差异,保证评测的客观性和时效性。
(3)行业影响。作为中文领域权威测评社区,其评测结果被学界和产业界广泛引用,例如商汤 “日日新 5.0” 和百度文心大模型均通过 SuperCLUE 验证技术突破,推动了中文 NLP 技术生态的迭代,为中文大模型的发展和优化提供了重要的参考依据,促进了中文大模型技术的不断进步和应用。
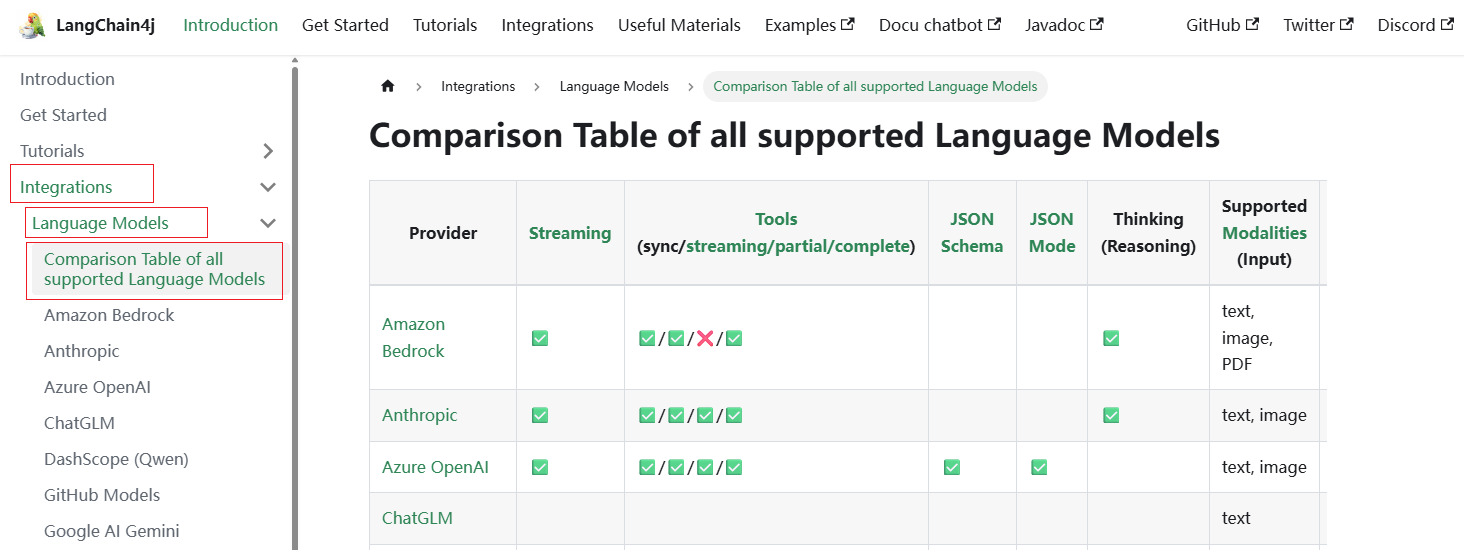
如果开发者想知道LangChain4j所支持接入的大模型,则可以点击 这里 进行查阅: