向量存储
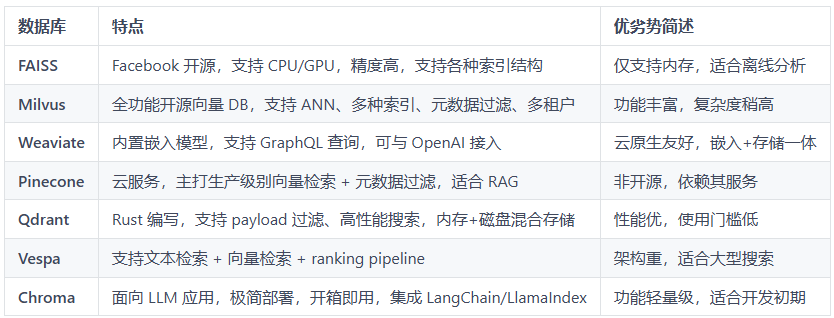
主流向量数据库对比
点击 这里,查看langchain4j对于向量存储的支持说明:
下图是主流的向量数据库的对比:
研发 / 原型阶段
- 推荐:FAISS(本地),Chroma
- 优点:轻量、易用、社区丰富
构建 Web 应用 / 小中型系统
- 推荐:Qdrant,Weaviate,Milvus-lite
- 优点:支持
REST/gRPC/客户端SDK,带元数据过滤,可集成 LangChain
大规模生产部署 / 高并发
- 推荐:Milvus(完整集群),Pinecone(托管),Vespa(超大规模)
- 优点:高可扩展性,多副本,支持异构资源
Pinecone简介
之前我们使用InMemoryEmbeddingStore作为向量存储,但是不建议在生产中使用基于内存的向量存储,因此接下来我们使用Pinecone作为向量数据库。
点击 这里,查看Pinecone的官方网站,用户默认有2GB的免费存储空间。之后进行注册、登录和使用。
Pinecone使用
【得分的含义】
在向量检索场景中,当我们把查询文本转换为向量后,会在嵌入存储(EmbeddingStore)里查找与之最相似的向量(这些向量对应文档片段的内容)。为了衡量查询向量和存储向量之间的相似程度,会使用某种相似度计算方法(如余弦相似度等)来得出一个数值,这个数值就是得分。得分越高,表明查询向量和存储向量越相似,对应的文档片段与查询文本的相关性也就越高。
【得分的作用】
(1)筛选结果:通过设置minScore 阈值,能够过滤掉那些与查询文本相关性较低的结果。在代码中,minScore(0.8) 意味着只有得分大于等于 0.8 的结果才会被返回,低于这个阈值的结果会被舍弃。这样可以确保返回的结果是与查询文本高度相关的,提升检索结果的质量。
(2)控制召回率和准确率:调整 minScore 的值可以在召回率和准确率之间进行权衡。如果把阈值设置得较低,那么更多的结果会被返回,召回率会提高,但可能会包含一些相关性不太强的结果,导致准确率下降。反之,如果把阈值设置得较高,返回的结果数量会减少,准确率会提高,但可能会遗漏一些相关的结果,使得召回率降低。在实际应用中,需要根据具体的业务需求来合理设置minScore的值。
【一个例子】
假设我们有一个关于水果的文档集合,嵌入存储中存储了这些文档片段的向量。当我们使用 “苹果的营养价值” 作为查询文本时,向量检索会计算查询向量与存储向量的相似度得分。如果 minScore设置为 0.8,那么只有那些与 “苹果的营养价值” 相关性非常高的文档片段才会被返回,而一些只简单提及苹果但没有详细讨论其营养价值的文档片段可能由于得分低于 0.8 而不会被返回。
Pinecone集成
添加依赖
点击 链接,查看langchain4j对于Pinecone的支持说明:

在项目的pom文件中引入依赖:
1
2
3
4
5
| <!-- 集成pinecone -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>
|
配置向量存储对象
(1)在langchain4j中,EmbeddingStore接口提供了统一的API,使得开发者可以很方便切换不同的向量数据库实现。
(2)EmbeddingStore的主要功能包括:
- 存储嵌入向量。将文本或其他数据转换为嵌入向量后,存储到向量数据库中。
- 相似度搜索。根据输入的查询向量,检索与之相似的嵌入向量,实现语义搜索。
- 关联原始数据。可以将嵌入向量与原始的
TextSegment数据一起存储,便于在检索时获取完整的上下文信息。
在项目的config包内定义一个名为 EmbeddingStoreConfig 的配置类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore(){
return PineconeEmbeddingStore.builder()
.apiKey("your_apiKey")
.index("yusi-index")
.nameSpace("yusi-namespace")
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS").region("us-east-1")
.dimension(embeddingModel.dimension()).build()).build();
}
}
|
简单解释一下上述代码的含义:
(1)apiKey:设置对应的apiKey;
(2)index:设置对应的索引,如果指定的索引名称不存在,那么将创建一个新的索引;
(3)nameSpace:设置对应的命名空间,如果指定的命名空间不存在,那么将创建一个新的命名空间;
(4)cloud:指定索引部署在AWS云服务上;
(5)region:指定索引所在AWS的区域为us-east-1;
(6)dimension:指定索引的向量维度,该维度与embeddedModel生成的向量维度相同。
实际上这些参数可以参考下面创建索引时的步骤来获取:
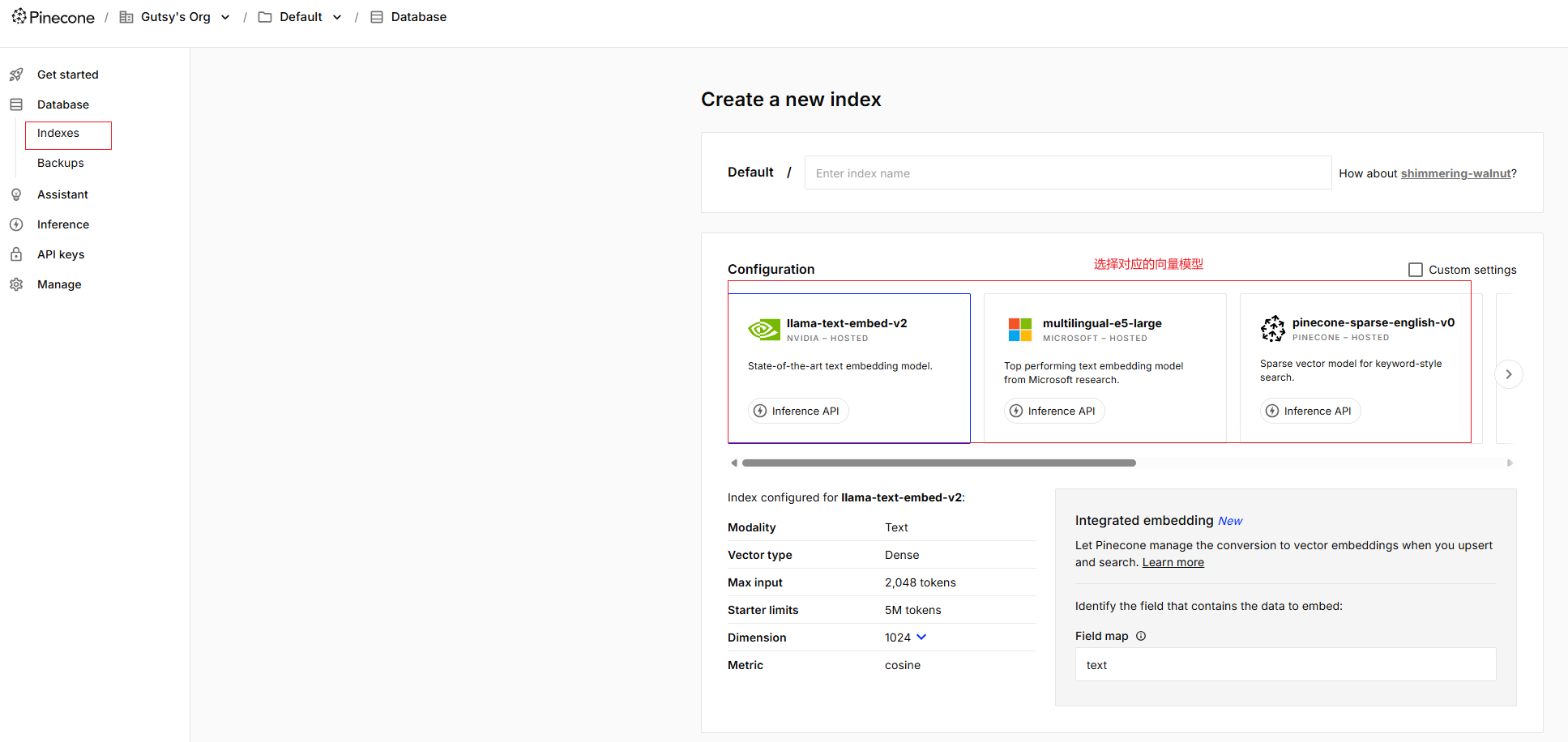

测试向量存储
修改EmbeddingController中的代码为如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Slf4j
@RestController
@RequestMapping("/embedding")
public class EmbeddingController {
@Autowired
private OllamaEmbeddingModel ollamaEmbeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* 测试向量存储
*/
@GetMapping("/testEmbeddingStore")
public String testEmbeddingStore(){
//将文本转换成向量
TextSegment textSegment = TextSegment.from("你好");
//获取向量
Embedding embedding = ollamaEmbeddingModel.embed(textSegment).content();
//添加向量
embeddingStore.add(embedding, textSegment);
return "success";
}
}
|
之后访问如下链接:
1
| http://localhost:8080/embedding/testEmbeddingStore
|
页面返回success信息后,刷新Pinecone的index界面:

可以看到此时已经有一个向量存储在Pinecone服务器上了。
相似度匹配
所谓相似度匹配,即接收请求获取问题,将问题转换为向量,在 Pinecone 向量数据库中进行相似度搜索,找到最相似的文本片段,并将其文本内容返回给客户端。
第一步,调用前面测试向量存储的接口,往里面存入文本内容为“我喜欢吃西瓜”的向量数据,以便后面使用:

第二步,修改EmbeddingController中的代码为如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| @Slf4j
@RestController
@RequestMapping("/embedding")
public class EmbeddingController {
@Autowired
private OllamaEmbeddingModel ollamaEmbeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* 测试向量搜索
*/
@GetMapping("/testEmbeddingSearch")
public String testEmbeddingSearch(){
//提问,并将问题转成向量数据
Embedding queryEmbedding = ollamaEmbeddingModel.embed("你最喜欢什么水果?")
.content();
//创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) // 设置最大返回结果数量
.minScore(0.1) // 设置最小得分阈值
.build();
//根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore
.search(searchRequest);
//获取搜索结果,获取最相似的向量,返回一个
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
//获取匹配项的相似度得分
log.info("相似度得分:{}",embeddingMatch.score());
// 获取匹配项的向量数据
String text = embeddingMatch.embedded().text();
//获取匹配项的元数据,即文本结果
log.info("匹配项的元数据:{}",text);
return text;
}
}
|
简单解释一下上述代码的含义:
(1)ollamaEmbeddingModel.embed().content():使用的是Ollama因此使用对应的模型进行提问,并将问题转成向量数据;
(2)EmbeddingSearchRequest.builder().build():用于创建搜索请求对象,其中maxResults()用于设置最大返回结果数量,而minScore()用于设置最小得分阈值;
(3)embeddingStore.search():用于根据搜索请求 searchRequest 在向量存储中进行相似度搜索;
(4)searchResult.matches().get(0):searchResult.matches()获取搜索结果中的匹配项列表,然后调用get(0)从匹配项列表中获取第一个匹配项;
(5)embeddingMatch.score():获取匹配项的相似度得分;
(6)embeddingMatch.embedded().text():用于获取匹配项的元数据,即文本结果。
之后访问如下链接:
1
| http://localhost:8080/embedding/testEmbeddingSearch
|
打开控制台,输出如下信息:
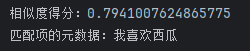
可以看到它正确的输出了我们需要的数据。可见EmbeddingSearchRequest的核心作用是构建一个搜索请求,包含以下关键参数:
- queryEmbedding:待搜索的查询向量,通常由嵌入模型(如
EmbeddingModel)生成。
- filter(可选):用于根据元数据(如作者、标签等)对搜索结果进行过滤。
- maxResults:指定返回的最大结果数量。
- minScore(可选):设置结果的最小相似度得分阈值,低于该值的结果将被排除。
流式输出
点击 这里,了解langchain4j对于流式响应的支持说明:

这里我们返回选择Flux:
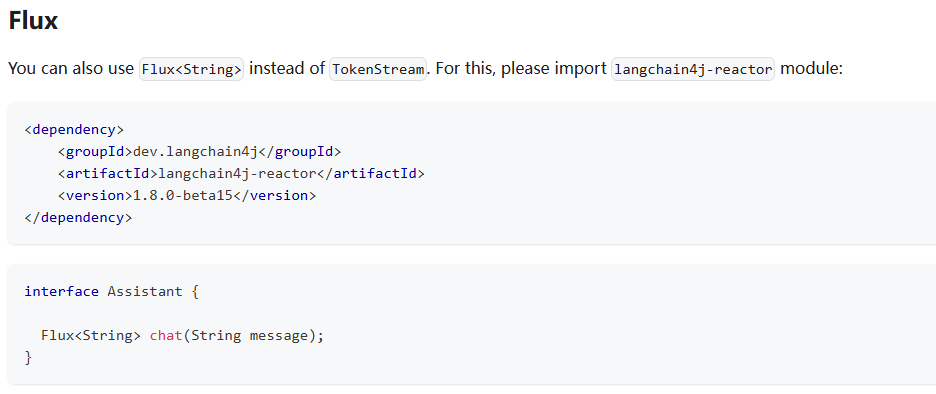
第一步,项目pom文件中引入如下依赖:
1
2
3
4
5
6
7
8
9
10
11
| <!--流式输出-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- 响应式编程 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
|
第二步,在项目的application.properties配置文件中新增如下配置项:
1
2
3
4
5
6
7
| #ollama stream chatModel
langchain4j.ollama.streaming-chat-model.base-url=http://localhost:11434
langchain4j.ollama.streaming-chat-model.model-name=qwen3:1.7b
langchain4j.ollama.streaming-chat-model.temperature=0.8
langchain4j.ollama.streaming-chat-model.timeout=PT60S
langchain4j.ollama.streaming-chat-model.log-requests=true
langchain4j.ollama.streaming-chat-model.log-responses=true
|
第三步,到项目的assistant包内,在里面定义一个名为StreamAssistant的类,专门用于进行流式输出,其中的streamingChatModel属性设置为ollamaStreamingChatModel,同时方法返回的是一个Flux对象:
1
2
3
4
5
6
7
8
9
10
| @AiService(wiringMode = AiServiceWiringMode.EXPLICIT,
streamingChatModel = "ollamaStreamingChatModel",
chatMemoryProvider = "chatMemoryProvider",
tools = "mathTools",
contentRetriever = "contentRetriever"
)
public interface StreamAssistant {
@SystemMessage(fromResource = "prompts/assistantV1.txt")
Flux<String> chat(@MemoryId int memoryId , @UserMessage String userMessage);
}
|
第四步,回到controller包中,我们新创建一个名为ChatController的类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Slf4j
@RestController
public class ChatController {
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Autowired
private StreamAssistant streamAssistant;
/**
* 聊天
*/
@PostMapping("/chat")
public String chat(@RequestBody ChatFormDTO chatFormDTO){
return separateChatAssistant.chat(chatFormDTO.getMemoryId(),
chatFormDTO.getMessage());
}
/**
* 流式聊天
*/
@PostMapping("/streamChat")
public Flux<String> streamChat(@RequestBody ChatFormDTO chatFormDTO){
return streamAssistant.chat(chatFormDTO.getMemoryId(),
chatFormDTO.getMessage());
}
}
|
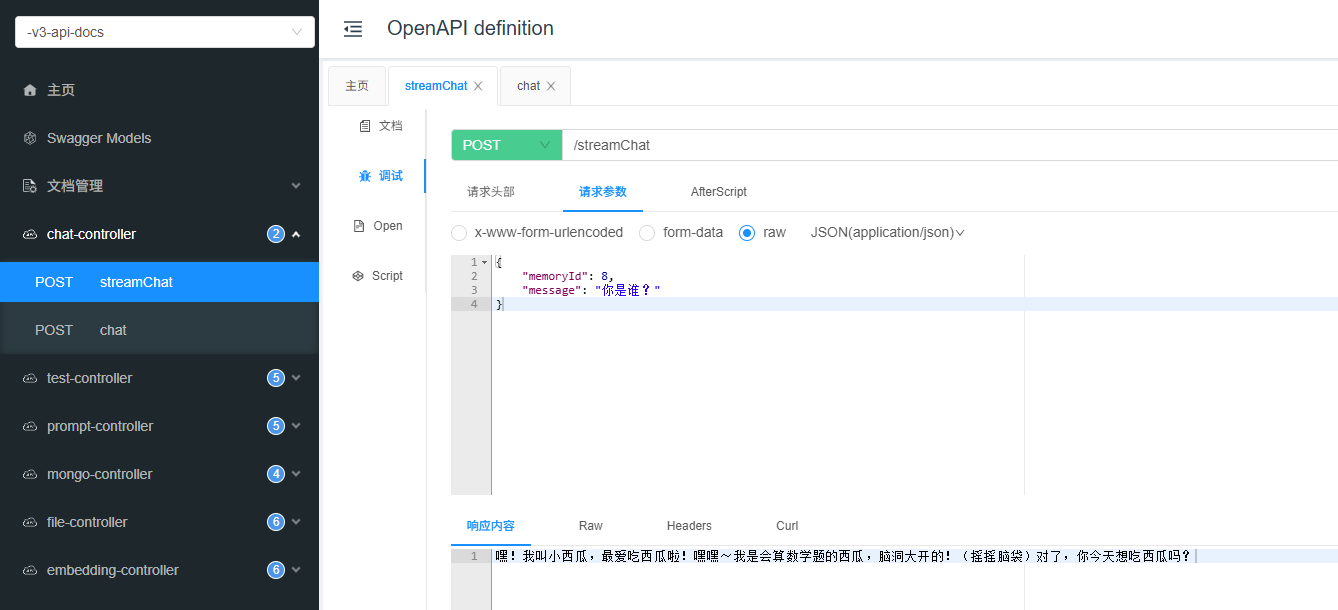
第五步,启动项目进行测试。访问如下地址,获取接口文档:
1
| http://localhost:8080/doc.html
|
然后我们点击对应的chat测试接口:
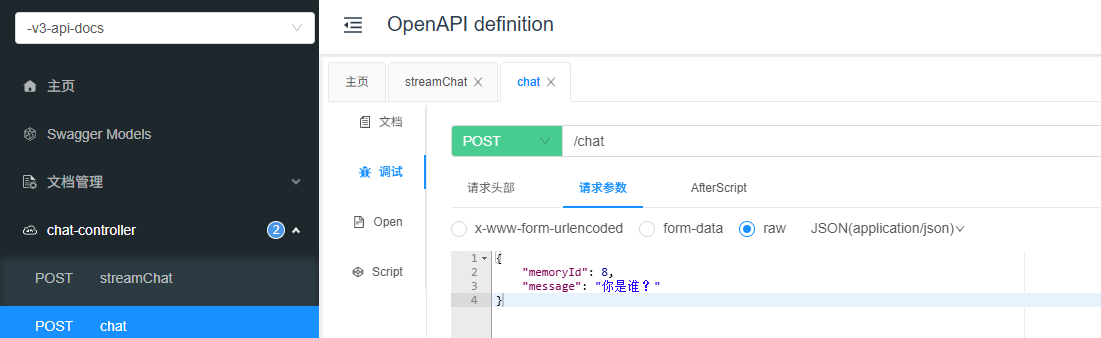
再来看一下流式输出接口: